lovemenow
Пользователи
-
Регистрация
-
В сети
Everything posted by lovemenow
-
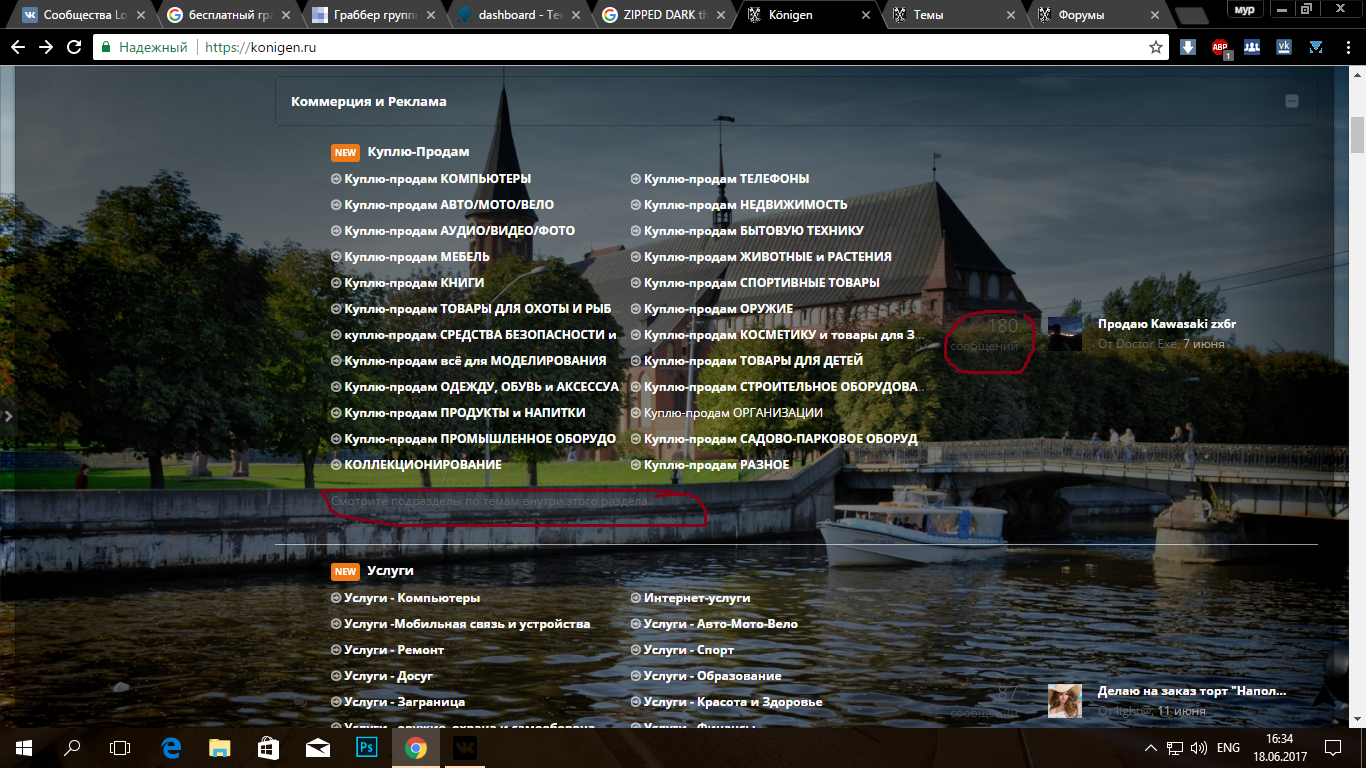
Вот эти два и не отображаются) в фоне
-
Да конечно
-
Почему не отображается фон?
-
Спасибо я разобрался! Проблема в то что когда пользователи вставляют из чужого сайта текст он черный, как сделать его белым
-
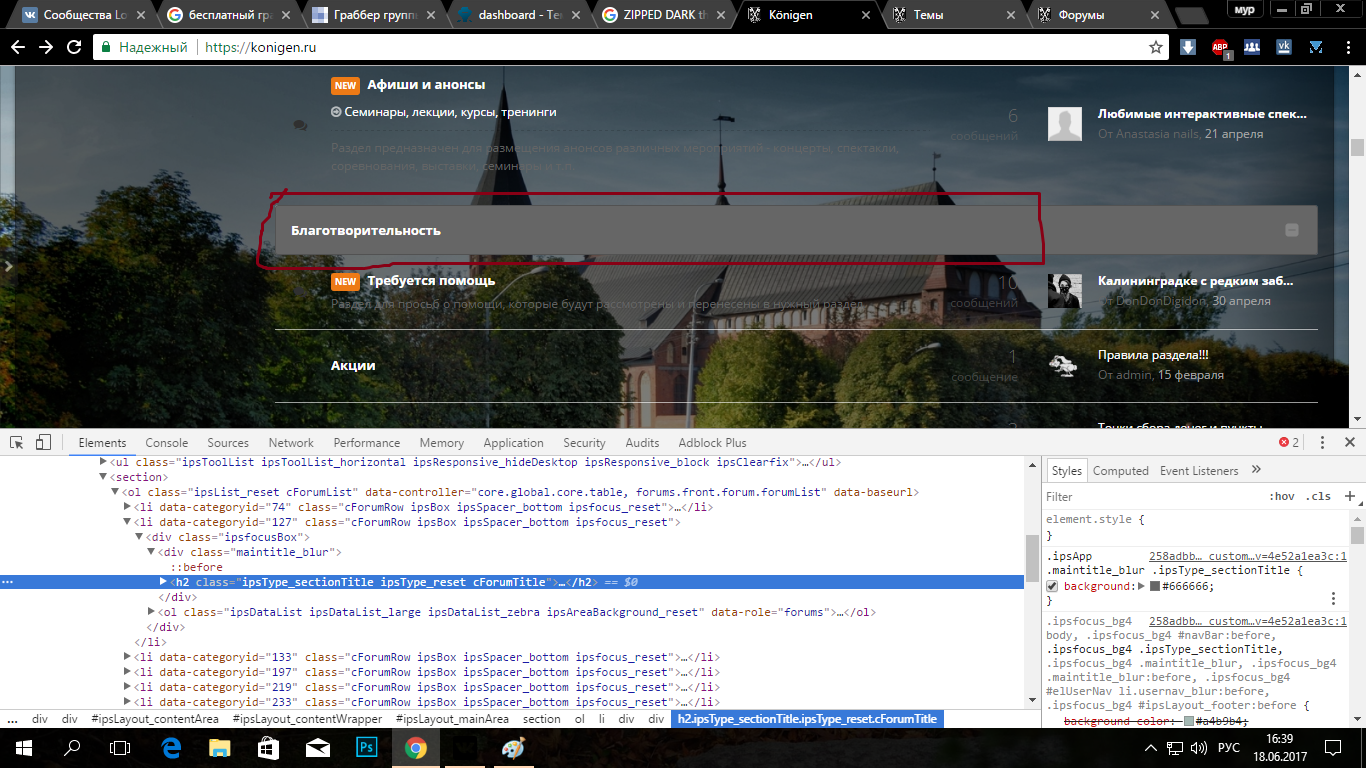
спасибо вам большое Не видно сообщения предыдущих комментариев! Где можно изменить это ?!
-
все обыскал)) нету) konigen.ru Прозрачность, извините
-
Доброй ночи! Не могу изменить header в стиле chameleon помогите?))
-
Доброй ночи , форумчане !
-
хоть попытался)), кто возьмется сделать то, что я хочу? !и сколько будет стоить! ? Заранее спасибо !
-
Мотивация не помогла?
-
? Хоть что то напишите, типа нет сам делай или вообще народ наглый с одним помогли,а он еще и еще Мы вместе создаем новый стиль, тему)
-
С этим ничего нельзя сделать?! )))
-
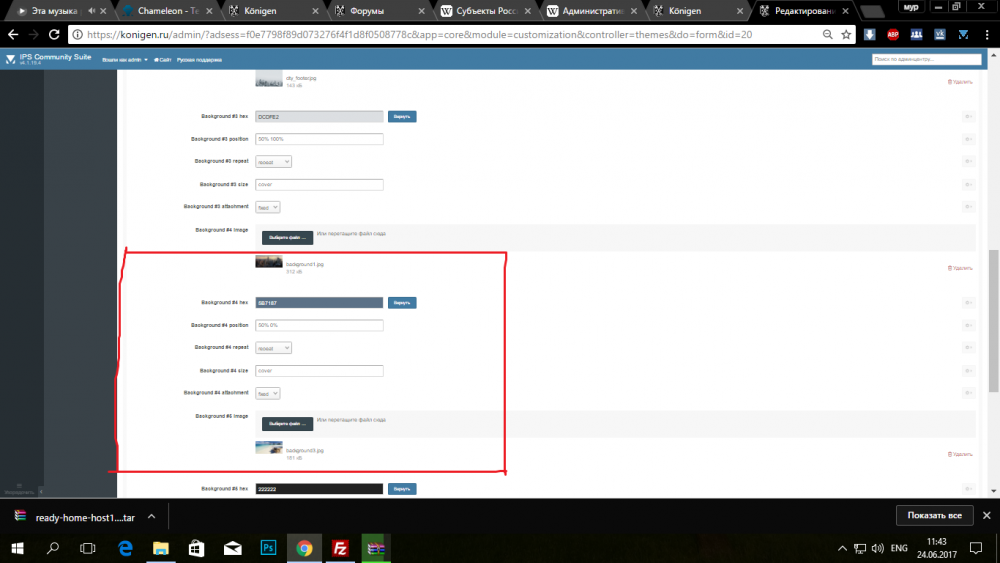
Еще вот это помогите) и вот эту рамку не могу найти
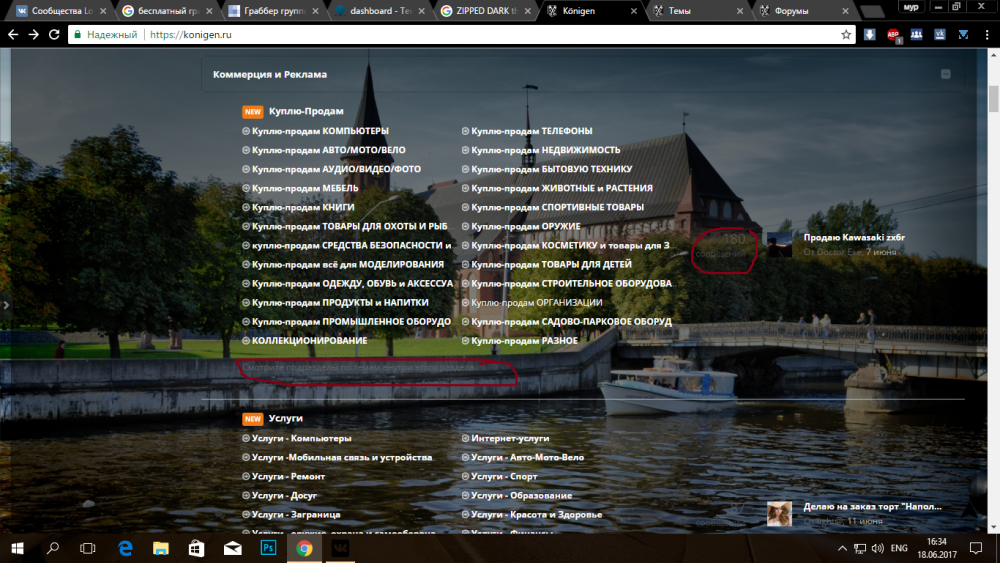
-
Спасибо большое! еще 1 вопрос:" а цвет текста не подскажите где искать?"
-
Тишина, ничего не изменилось
-
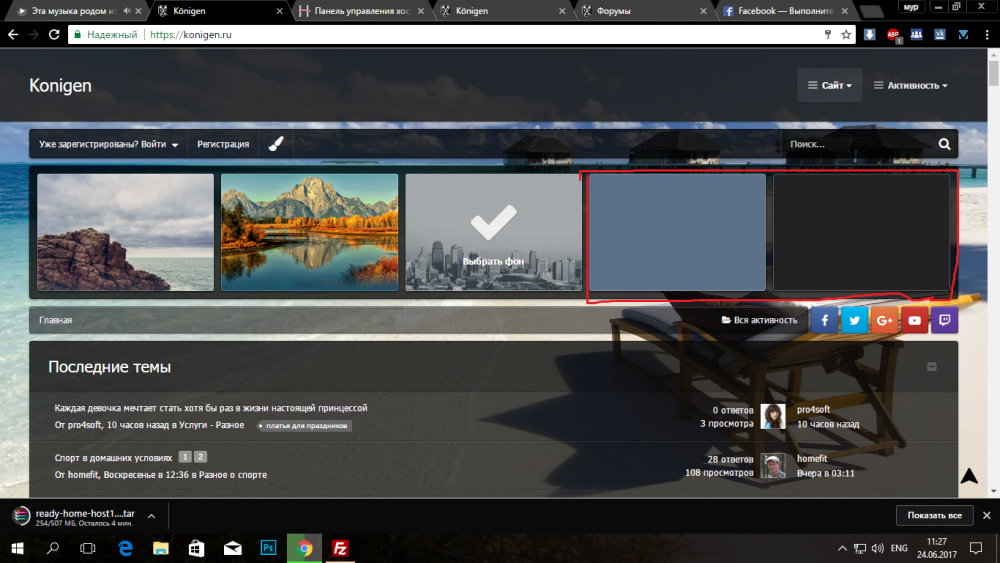
https://konigen.ru/ ссылка на форум)) левую часть получилось сделать прозрачным, а вот основной стиль нет)
-
Помогите сделать прозрачный фон типа того
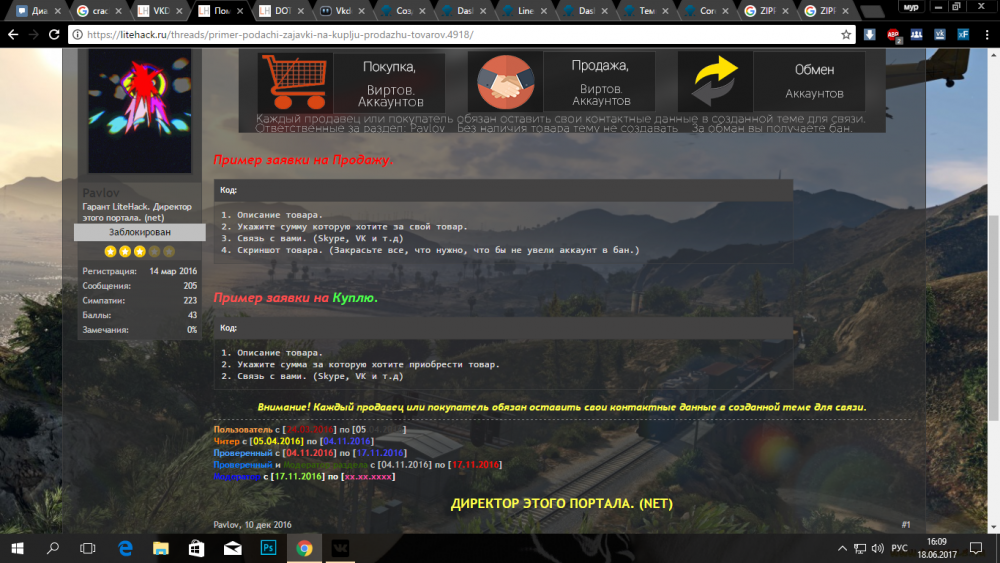
-
Все есть посетители заходят, глубина просмотров нормально! даже с гугла и я с яндекса начали приходить! Понт в том что люди не задерживаются!. Как можно их задержать!? Какие можно я книги прочел по сео, ролики просмотрел ?)). Все по им советам делаю! Но результат есть, но не такой какой хочется))
-
Спасибо Вам огромное, душу успокоили)
-
Крутил вертел))) Для мобильных 65, для пк 85. Внимания вопрос это нормально, что такой результат?! ExpiresActive On ExpiresDefault A0 # 1 YEAR <FilesMatch "\.(flv|ico|pdf|avi|mov|ppt|doc|mp3|wmv|wav)$"> ExpiresDefault A29030400 </FilesMatch> # 1 WEEK <FilesMatch "\.(jpg|jpeg|png|gif|swf)$"> ExpiresDefault A604800 </FilesMatch> # 3 HOUR <FilesMatch "\.(txt|xml|js|css)$"> ExpiresDefault A10800" </FilesMatch> # BEGIN Compress text files AddOutputFilterByType DEFLATE text/html text/plain text/xml application/xml application/xhtml+xml text/css text/javascript application/javascript application/x-javascript # END Compress text files # BEGIN Expire headers ExpiresActive On ExpiresDefault "access plus 5 seconds" ExpiresByType image/x-icon "access plus 2592000 seconds" ExpiresByType image/jpeg "access plus 2592000 seconds" ExpiresByType image/png "access plus 2592000 seconds" ExpiresByType image/gif "access plus 2592000 seconds" ExpiresByType application/x-shockwave-flash "access plus 2592000 seconds" ExpiresByType text/css "access plus 604800 seconds" ExpiresByType text/javascript "access plus 216000 seconds" ExpiresByType application/javascript "access plus 216000 seconds" ExpiresByType application/x-javascript "access plus 216000 seconds" ExpiresByType text/html "access plus 600 seconds" ExpiresByType application/xhtml+xml "access plus 600 seconds" # END Expire headers # BEGIN Cache-Control Headers Header set Cache-Control "public" Header set Cache-Control "public" Header set Cache-Control "private" Header set Cache-Control "private, must-revalidate" Header append Vary: Accept-Encoding Header set Cache-Control "max-age=43200" Header set Cache-Control "max-age=604800" Header set Cache-Control "max-age=2592000" Header unset Cache-Control # END Cache-Control Headers # BEGIN Turn ETags Off FileETag None # END Turn ETags Off #Gzip сжатие с помощью модуля mod_deflate - начало <ifModule mod_deflate.c> AddOutputFilterByType DEFLATE text/html text/plain text/xml application/xml application/xhtml+xml text/css text/javascript application/javascript application/x-javascript </ifModule> ##Gzip сжатие с помощью модуля mod_deflate - конец ##Gzip сжатие с помощью модуля mod_gzip - начало <IfModule mod_gzip.c> mod_gzip_on Yes mod_gzip_dechunk Yes mod_gzip_item_include file \.(html?|txt|css|js|php|pl)$ mod_gzip_item_include mime ^text\.* mod_gzip_item_include mime ^application/x-javascript.* mod_gzip_item_include mime ^application/x-font-woff.* mod_gzip_item_exclude rspheader ^Content-Encoding:.*gzip.* </IfModule> ##Gzip сжатие с помощью модуля mod_gzip - конец ##Кэширование с помощью модуля mod_headers - начало <ifModule mod_headers.c> #кэшировать HTML и htm файлы на один день <FilesMatch "\.(html|htm)$"> Header set Cache-Control "max-age=43200" </FilesMatch> #кэшировать CSS, javascript и текстовые файлы на одну неделю <FilesMatch "\.(js|css|txt)$"> Header set Cache-Control "max-age=604800" </FilesMatch> #кэшировать Flash и изображения на месяц <FilesMatch "\.(flv|swf|ico|gif|jpg|jpeg|png)$"> Header set Cache-Control "max-age=2592000" </FilesMatch> #отключить кэширование <FilesMatch "\.(pl|php|cgi|spl|scgi|fcgi)$"> Header unset Cache-Control </FilesMatch> </IfModule> ##Кэширование с помощью модуля mod_headers - конец ##Кэширование с помощью модуля mod_expires - начало <ifModule mod_expires.c> ExpiresActive On #по умолчанию кеш в 5 секунд ExpiresDefault "access plus 5 seconds" #кэшировать Flash и изображения на месяц ExpiresByType image/x-icon "access plus 2592000 seconds" ExpiresByType image/jpeg "access plus 2592000 seconds" ExpiresByType image/png "access plus 2592000 seconds" ExpiresByType image/gif "access plus 2592000 seconds" ExpiresByType application/x-shockwave-flash "access plus 2592000 seconds" #кэшировать CSS, javascript и текстовые файлы на одну неделю ExpiresByType text/css "access plus 604800 seconds" ExpiresByType text/javascript "access plus 604800 seconds" ExpiresByType application/javascript "access plus 604800 seconds" ExpiresByType application/x-javascript "access plus 604800 seconds" #кэшировать HTML и htm файлы на один день ExpiresByType text/html "access plus 43200 seconds" #кэшировать XML файлы на десять минут ExpiresByType application/xhtml+xml "access plus 600 seconds" </ifModule> ##Кэширование с помощью модуля mod_expires - конец
-
function footer_enqueue_scripts() { # Удаляем JavaScript из заголовка remove_action('wp_head', 'wp_print_scripts'); remove_action('wp_head', 'wp_print_head_scripts', 9); remove_action('wp_head', 'wp_enqueue_scripts', 1); # Выводим в footer add_action('wp_footer', 'wp_print_scripts', 5); add_action('wp_footer', 'wp_enqueue_scripts', 5); add_action('wp_footer', 'wp_print_head_scripts', 5); } add_action('after_setup_theme', 'footer_enqueue_scripts'); Для ipb нет такой альтернативы?!
-
Добрый ночи! подскажите как можно их подлатать и добавить в кэш!? Уже перегуглил пол интернета, а ответа полного не нашёл - некоторые что-то пишут заумное, как вроди все профессионалы и всё понимают. Помогите, как их исправить - поподробнее.
-
Можете с тремя пунктами помочь, а то я немного накосячил форум начал ошибки выдавать )) Использование robots.txt Что такое файл robots.txt Как создать robots.txt Директива User-agent Директивы Disallow и Allow Использование спецсимволов * и $ Директива sitemap Директива Host Директива Crawl-delay Директива Clean-param Дополнительная информация Исключения Что такое файл robots.txt Robots.txt — текстовый файл, который содержит параметры индексирования сайта для роботов поисковых систем. Также рекомендуем просмотреть урок Как управлять индексированием сайта. Как создать robots.txt В текстовом редакторе создайте файл с именем robots.txt и заполните его в соответствии с представленными ниже правилами. Проверьте файл в сервисе Яндекс.Вебмастер (пункт меню Анализ robots.txt). Загрузите файл в корневую директорию вашего сайта. Директива User-agent Робот Яндекса поддерживает стандарт исключений для роботов с расширенными возможностями, которые описаны ниже. В роботе Яндекса используется сессионный принцип работы, на каждую сессию формируется определенный пул страниц, которые планирует загрузить робот. Сессия начинается с загрузки файла robots.txt. Если файл отсутствует, не является текстовым или на запрос робота возвращается HTTP-статус отличный от 200 OK, робот считает, что доступ к документам не ограничен. В файле robots.txt робот проверяет наличие записей, начинающихся с User-agent:, в них учитываются подстроки Yandex (регистр значения не имеет) или * . Если обнаружена строка User-agent: Yandex, директивы для User-agent: * не учитываются. Если строки User-agent: Yandex и User-agent: * отсутствуют, считается, что доступ роботу не ограничен. Следующим роботам Яндекса можно указать отдельные директивы: 'YandexBot' — основной индексирующий робот; 'YandexDirect' — скачивает информацию о контенте сайтов-партнеров Рекламной сети, чтобы уточнить их тематику для подбора релевантной рекламы, интерпретирует robots.txt особым образом; 'YandexDirectDyn' — робот генерации динамических баннеров, интерпретирует robots.txt особым образом; 'YandexMedia' — робот, индексирующий мультимедийные данные; 'YandexImages' — индексатор Яндекс.Картинок; 'YaDirectFetcher' — робот Яндекс.Директа, интерпретирует robots.txt особым образом; 'YandexBlogs'поиска по блогам — робот , индексирующий посты и комментарии; 'YandexNews' — робот Яндекс.Новостей; 'YandexPagechecker' — валидатор микроразметки; ‘YandexMetrika’ — робот Яндекс.Метрики; ‘YandexMarket’— робот Яндекс.Маркета; ‘YandexCalendar’ — робот Яндекс.Календаря. Если обнаружены директивы для конкретного робота, директивы User-agent: Yandex и User-agent: * не используются. Пример: User-agent: YandexBot # будет использоваться только основным индексирующим роботом Disallow: /*id= User-agent: Yandex # будет использована всеми роботами Яндекса Disallow: /*sid= # кроме основного индексирующего User-agent: * # не будет использована роботами Яндекса Disallow: /cgi-bin Директивы Disallow и Allow Чтобы запретить доступ робота к сайту или некоторым его разделам, используйте директиву Disallow. Примеры: User-agent: Yandex Disallow: / # блокирует доступ ко всему сайту User-agent: Yandex Disallow: /cgi-bin # блокирует доступ к страницам, # начинающимся с '/cgi-bin' В соответствии со стандартом перед каждой директивой User-agent рекомендуется вставлять пустой перевод строки. Символ # предназначен для описания комментариев. Все, что находится после этого символа и до первого перевода строки не учитывается. Чтобы разрешить доступ робота к сайту или некоторым его разделам, используйте директиву Allow Примеры: User-agent: Yandex Allow: /cgi-bin Disallow: / # запрещает скачивать все, кроме страниц # начинающихся с '/cgi-bin' Примечание. Недопустимо наличие пустых переводов строки между директивами User-agent, Disallow и Allow. Совместное использование директив Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке. Таким образом, порядок следования директив в файле robots.txt не влияет на использование их роботом. Примеры: # Исходный robots.txt: User-agent: Yandex Allow: /catalog Disallow: / # Сортированный robots.txt: User-agent: Yandex Disallow: / Allow: /catalog # разрешает скачивать только страницы, # начинающиеся с '/catalog' # Исходный robots.txt: User-agent: Yandex Allow: / Allow: /catalog/auto Disallow: /catalog # Сортированный robots.txt: User-agent: Yandex Allow: / Disallow: /catalog Allow: /catalog/auto # запрещает скачивать страницы, начинающиеся с '/catalog', # но разрешает скачивать страницы, начинающиеся с '/catalog/auto'. Примечание. При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow. Директивы Allow и Disallow без параметров Если директивы не содержат параметры, учитывает данные следующим образом: User-agent: Yandex Disallow: # то же, что и Allow: / User-agent: Yandex Allow: # не учитывается роботом Использование спецсимволов * и $ При указании путей директив Allow и Disallow можно использовать спецсимволы * и $, задавая, таким образом, определенные регулярные выражения. Спецсимвол * означает любую (в том числе пустую) последовательность символов. Примеры: User-agent: Yandex Disallow: /cgi-bin/*.aspx # запрещает '/cgi-bin/example.aspx' # и '/cgi-bin/private/test.aspx' Disallow: /*private # запрещает не только '/private', # но и '/cgi-bin/private' Спецсимвол $ По умолчанию к концу каждого правила, описанного в файле robots.txt, приписывается спецсимвол *. Пример: User-agent: Yandex Disallow: /cgi-bin* # блокирует доступ к страницам # начинающимся с '/cgi-bin' Disallow: /cgi-bin # то же самое Чтобы отменить * на конце правила, можно использовать спецсимвол $, например: User-agent: Yandex Disallow: /example$ # запрещает '/example', # но не запрещает '/example.html' User-agent: Yandex Disallow: /example # запрещает и '/example', # и '/example.html' Спецсимвол $ не запрещает указанный * на конце, то есть: User-agent: Yandex Disallow: /example$ # запрещает только '/example' Disallow: /example*$ # так же, как 'Disallow: /example' # запрещает и /example.html и /example Директива sitemap Если вы используете описание структуры сайта с помощью файла sitemap, укажите путь к файлу в качестве параметра директивы sitemap (если файлов несколько, укажите все). Пример: User-agent: Yandex Allow: / sitemap: http://example.com/site_structure/my_sitemaps1.xml sitemap: http://example.com/site_structure/my_sitemaps2.xml Робот запомнит путь к файлу, обработает данные и будет использовать результаты при последующем формировании сессий загрузки. директива вот так включается?
-
Спасибо Вам огромное, а такой вопрос через соц сети(smm) эффективный способ раскрутки ?!
-
Доброе время суток! Поделитесь своим опытом раскрутку форума. Прочитал много по раскрутки форума или сайта, делал, как люди советовали в интернете. потратился , но результата , которого я ожидал практически нету. Заранее огромное спасибо